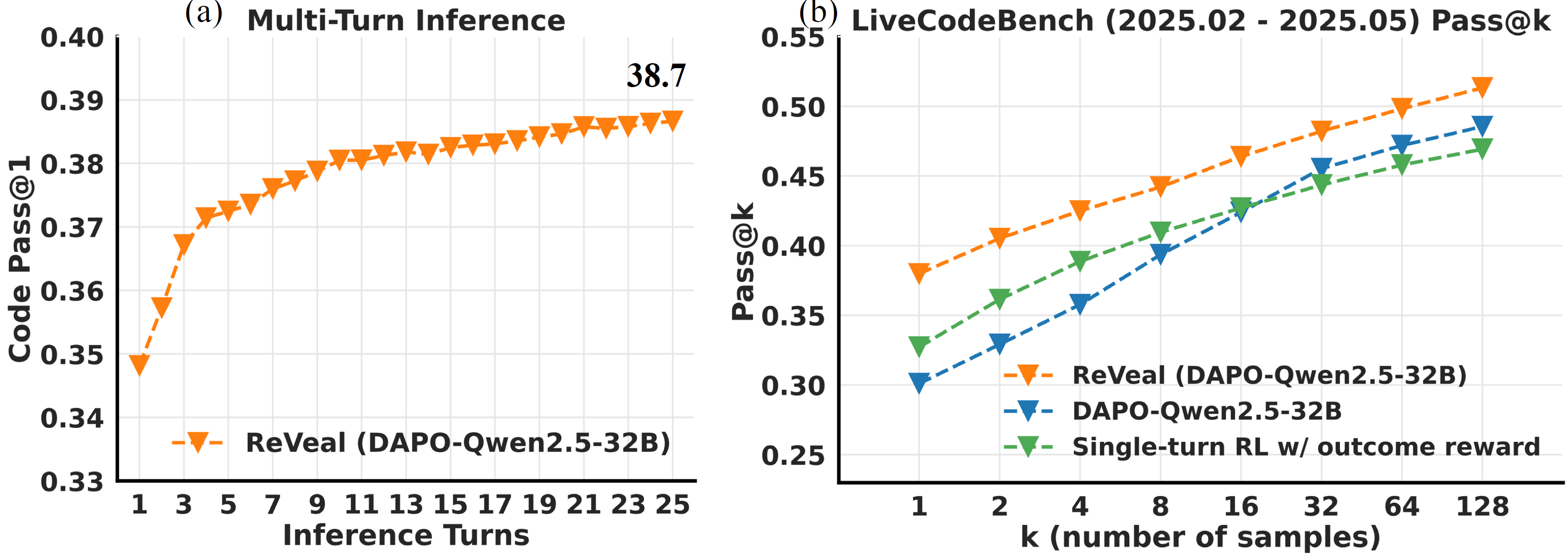
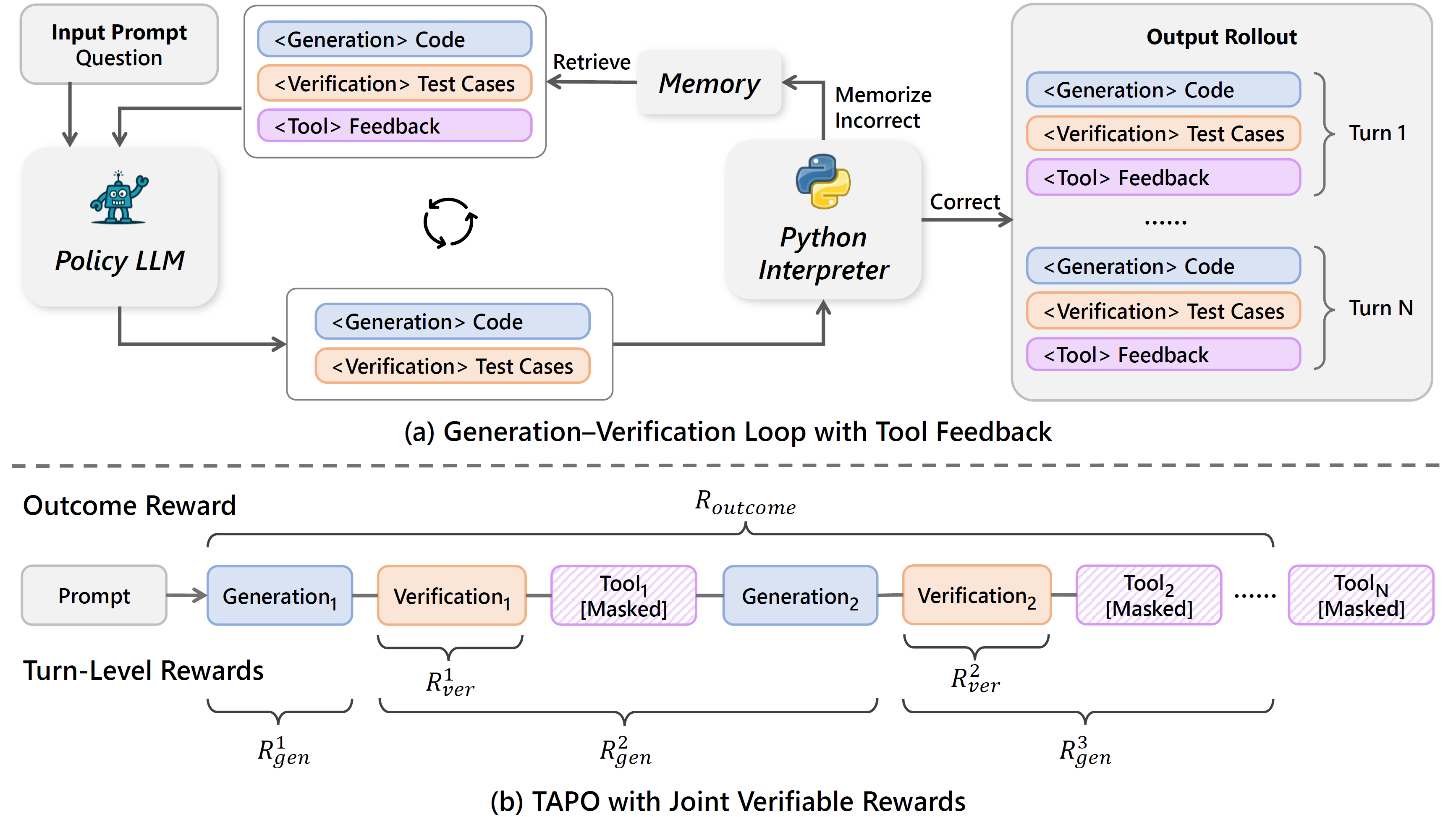
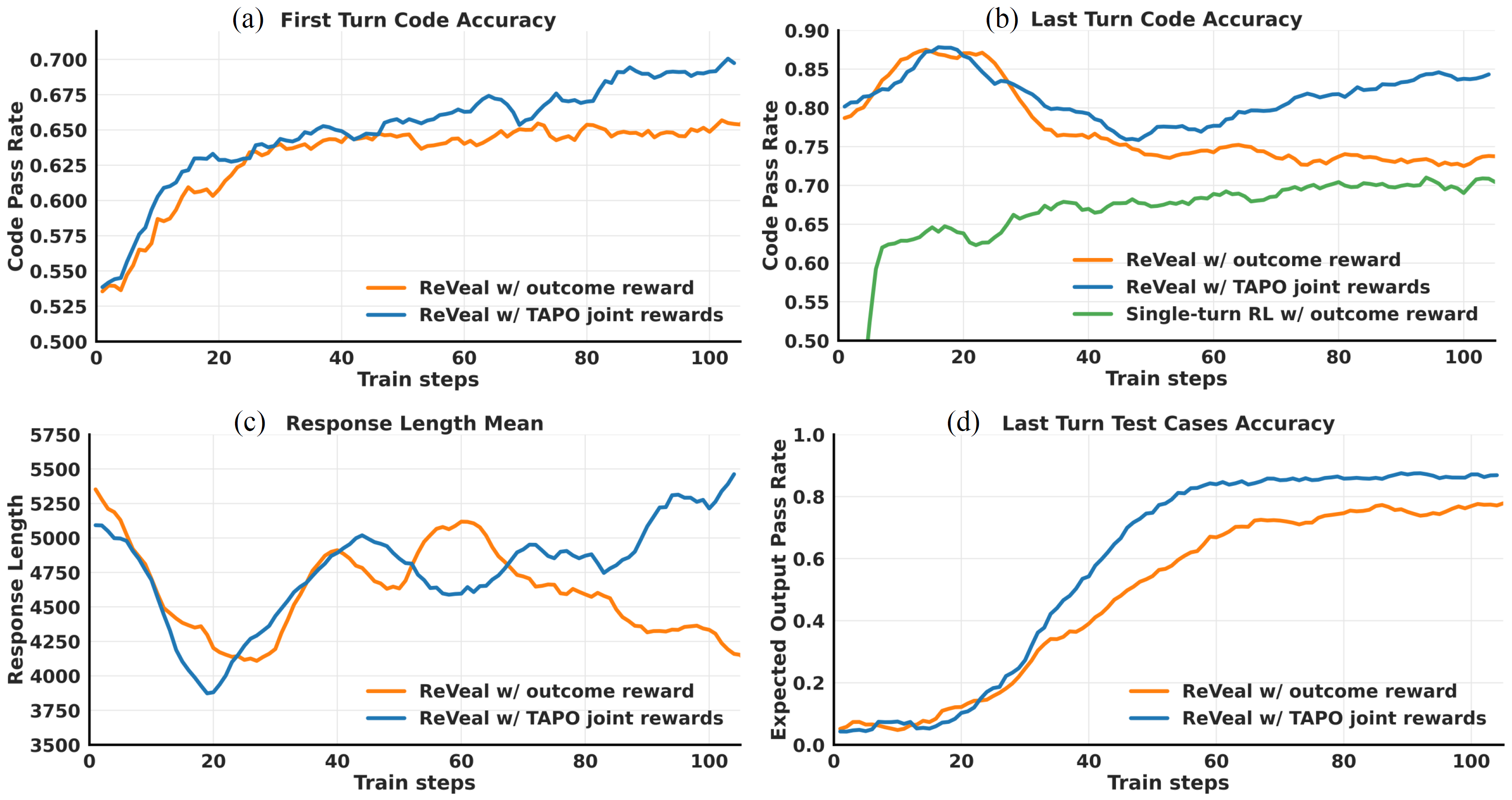
ReVeal is a multi-turn RL framework that enables code agents to engage in an iterative generation-verification loop via RL training. This framework decomposes long-horizon reasoning into alternating generation and verification turns. It introduces dense, verifiable rewards at each turn, enabling fine-grained optimization of both code quality and verification accuracy. To prevent adversarial reward gaming (e.g., generating trivial code to hack verification rewards), ReVeal incorporates robustness mechanisms and a customized RL algorithm tailored for the generation-verification interplay. This turn-level supervision not only explicitly optimizes self-verification and iterative refinement, but also enables effective verification-driven test-time scaling.
Multi-turn rollout: Below is the ReVeal Performing Iterative Generation and Verification. Instead of relying on the commonly used <think>-<answer> prompting, ReVeal adopts a more structured prompting format that explicitly decouples generation, verification, and tool feedback into an iterative loop using distinct tags.
As shown in the example, the model first reasons about the problem under <generation-think> and produces a candidate solution within <generation-answer>. It then initiates the verification phase, constructing a plan under <verification-think> by analyzing potential failure modes, edge conditions, and the intended behavior of the code. These test cases, either derived from the problem description or newly synthesized to expose likely errors, are specified under <verification-answer> for direct execution. The <tool-feedback> section captures execution results, including runtime errors, invalid test cases, as well as the expected output, actual output, and pass/fail judgment for each valid test case. This structured feedback provides fine-grained supervision and guidance for the next generation-verification cycle. Based on this feedback, the model identifies failed cases, diagnoses underlying errors, and revises both code solutions and verification plans accordingly. This process continues over multiple turns, allowing the model to progressively refine its outputs through next rounds of generation and verification - enabling self-improvement without requiring external critic models or predefined test cases.